Warum Exponentiation und Logarithmen in der Statistik wichtig sind.
Statistik
Logarithmen
Exponentiation
Likelihood
Log-Likelihood
Autor:in
Norman Markgraf
Veröffentlichungsdatum
4. Februar 2026
Geändert
28. März 2026
Warum Exponentiation und Logarithmen in der Statistik wichtig sind
Die Exponentiation und der Logarithmus sind wichtig in der Statistik, weil sie helfen, komplexe Zusammenhänge zu verstehen und zu modellieren. Hier sind einige Gründe, warum sie so wichtig sind:
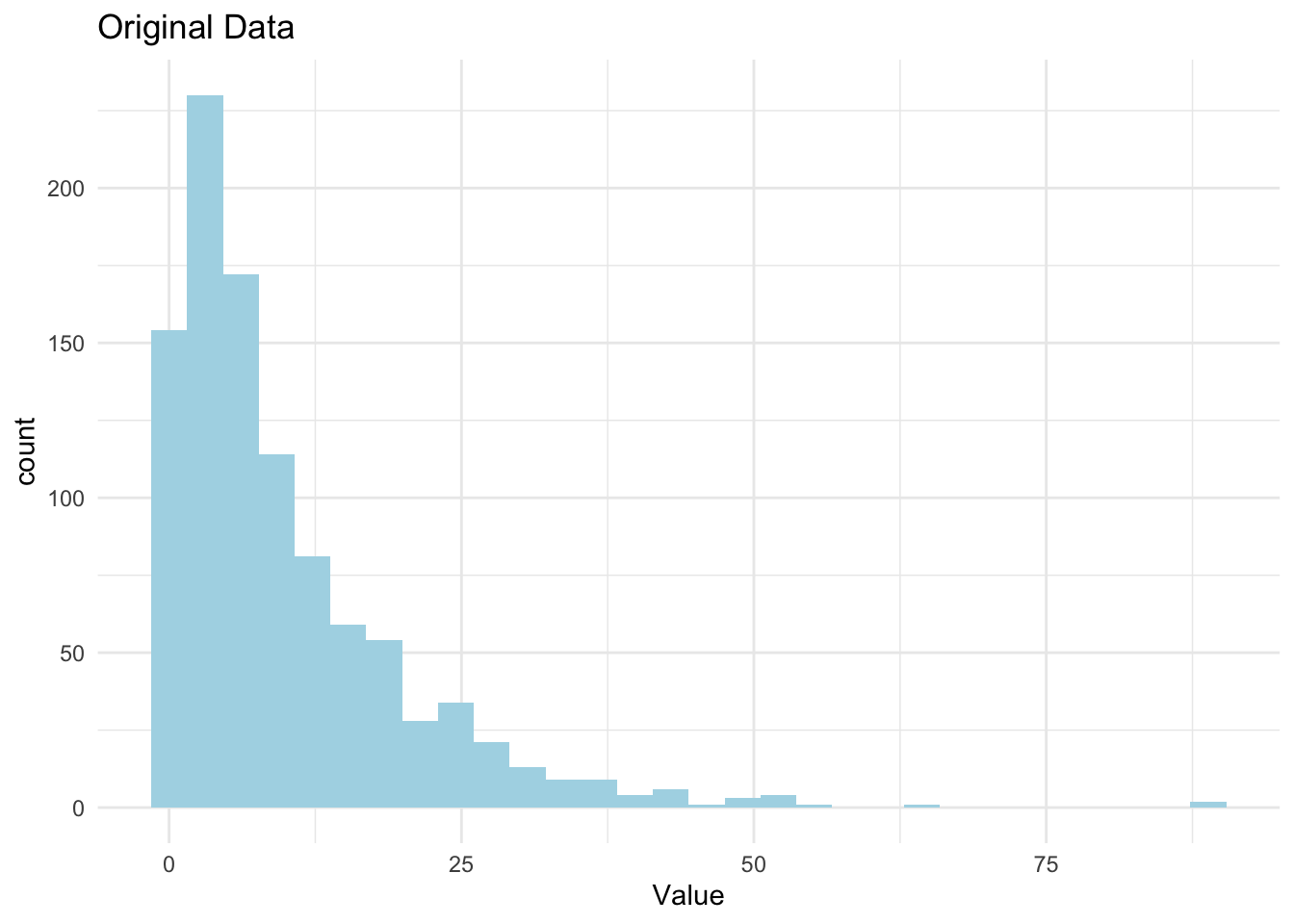
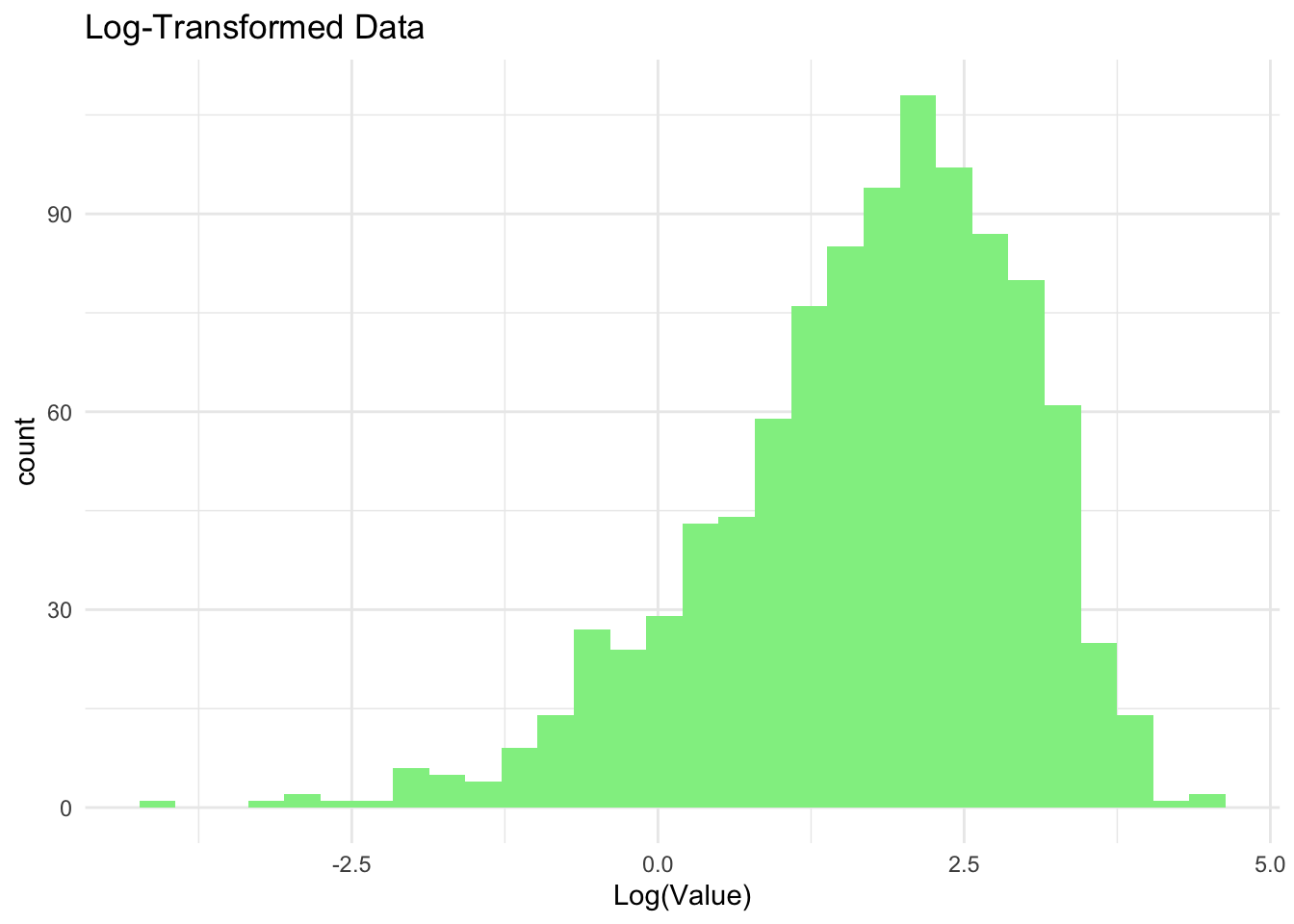
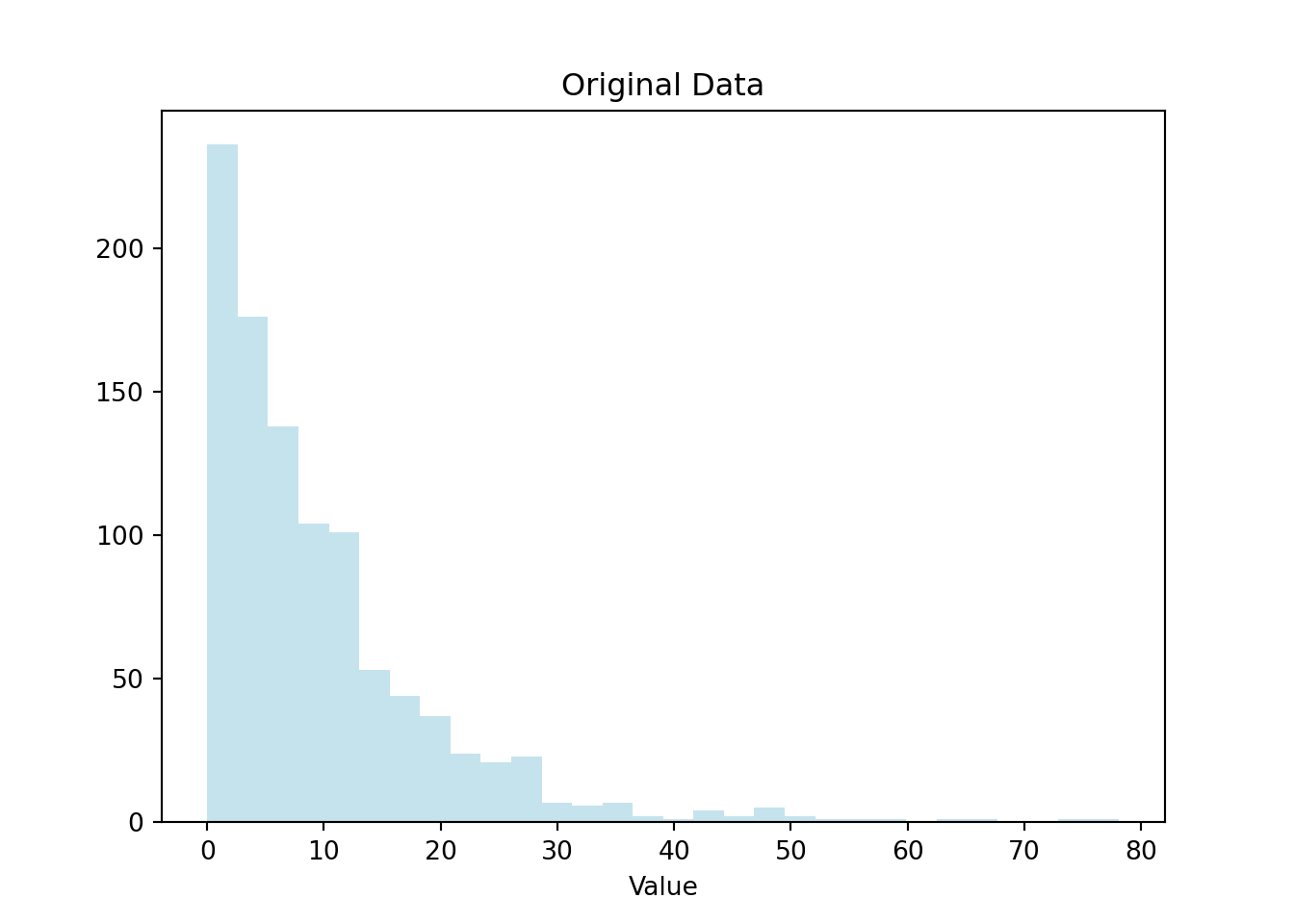
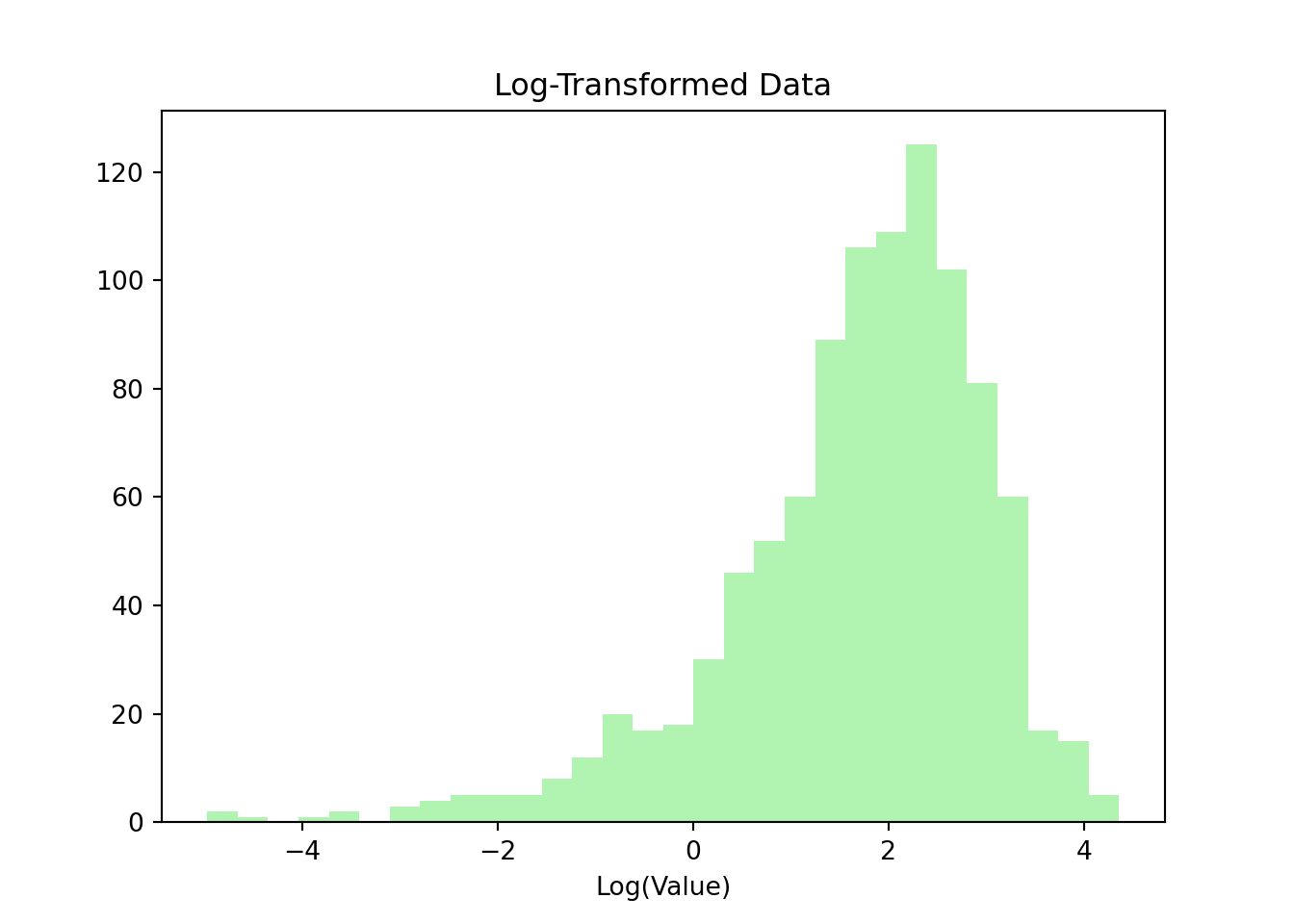
Daten Transformation: Viele statistische Modelle setzen voraus, dass die Daten normalverteilt sind. Durch die Anwendung von Logarithmen können schiefe Verteilungen in eine normalverteilte Form transformiert werden, was die Analyse erleichtert.
Multiplikative Beziehungen: In vielen Fällen sind die Beziehungen zwischen Variablen multiplikativ statt additiv. Logarithmen ermöglichen es, diese Beziehungen in eine additive Form zu überführen, was die Interpretation und Modellierung vereinfacht.
Wachstumsprozesse: Exponentielle Funktionen werden häufig verwendet, um Wachstumsprozesse zu modellieren, wie z.B. Bevölkerungswachstum oder Zinseszinsen. Logarithmen helfen dabei, diese Prozesse zu analysieren und zu verstehen.
Linearisierung: Viele nicht-lineare Modelle können durch die Anwendung von Logarithmen linearisiert werden, was die Anwendung von linearen Regressionsmethoden ermöglicht.
Skalierung: Logarithmische Skalen werden oft verwendet, um Daten darzustellen, die über mehrere Größenordnungen variieren, wie z.B. in der Finanzanalyse oder bei Messungen von Erdbebenstärken. Insgesamt sind Exponentiation und Logarithmen unverzichtbare Werkzeuge in der Statistik, die helfen, Daten zu transformieren, Beziehungen zu modellieren und komplexe Phänomene zu verstehen.
Datentransformation und Linearisierung mit Exponentiation und Logarithmes
library(ggplot2)# Beispiel in R: Log-Transformation einer schiefen Verteilungset.seed(2009)data =rexp(1000, rate =0.1) # Exponentielle Verteilungdf <-data.frame(x = data)ggplot(aes(x = x), data = df) +geom_histogram(bins =30, fill ="lightblue") +labs(title ="Original Data") +xlab("Value") +theme_minimal()
df_log <-data.frame(x =log(data)) # Log-Transformationggplot(aes(x = x), data = df_log) +geom_histogram(bins =30, fill ="lightgreen") +labs(title ="Log-Transformed Data") +xlab("Log(Value)") +theme_minimal()
import numpy as npimport matplotlib.pyplot as plt# Beispiel in Python: Log-Transformation einer schiefen Verteilungnp.random.seed(2009)# Exponentielle Verteilungdata = np.random.exponential(scale=10, size=1000)plt.hist(data, bins=30, color='lightblue', alpha=0.7)plt.title('Original Data')plt.xlabel('Value')plt.show()
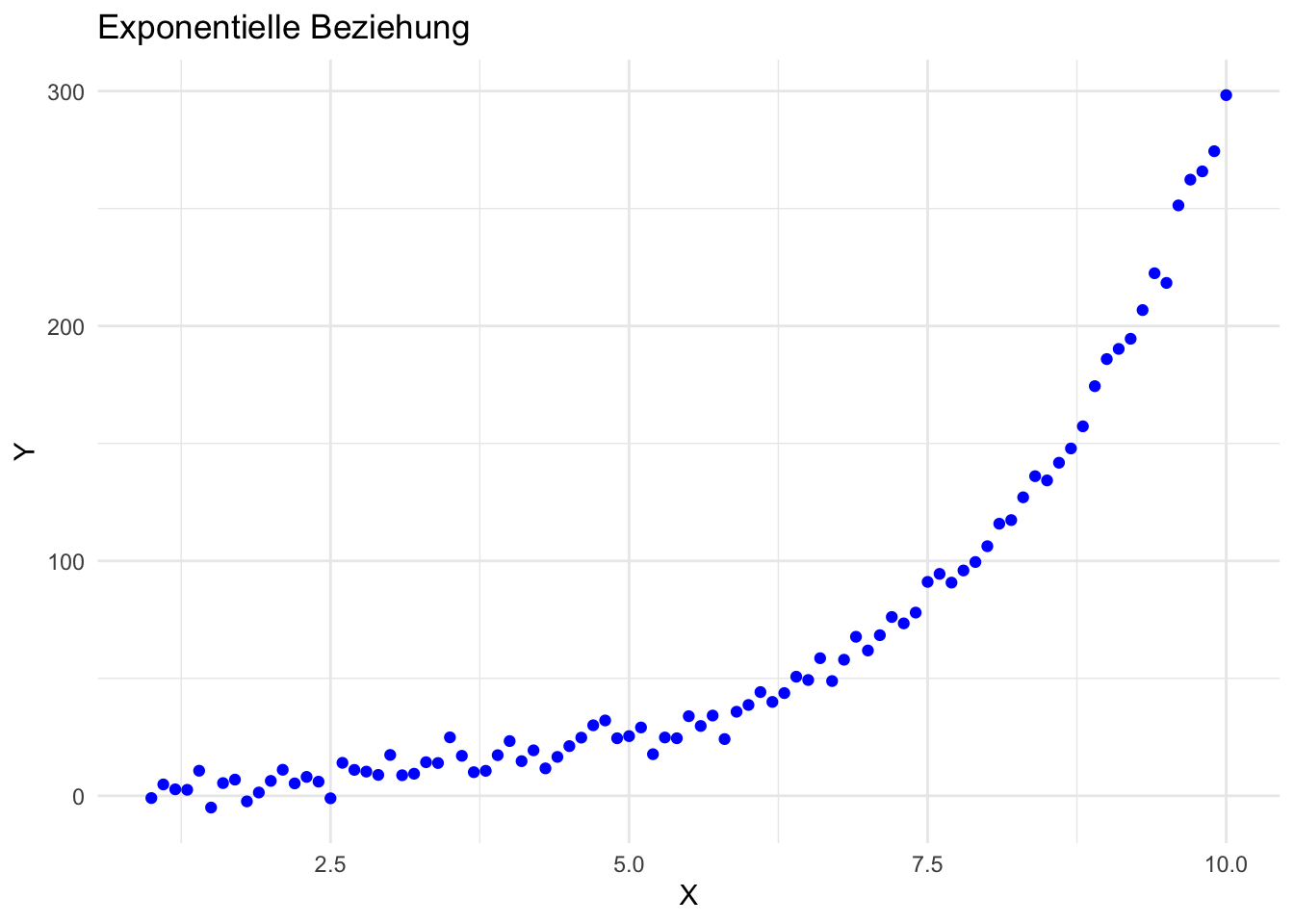
library(ggplot2)# Beispiel in R: Linearisierung einer exponentiellen Beziehungset.seed(2009)x <-seq(1, 10, by =0.1)y <-2*exp(0.5* x) +rnorm(length(x),mean =0, sd =5) # Exponentielle Beziehung mit Rauschendf <-data.frame(x = x, y = y)ggplot(aes(x = x, y = y), data = df) +geom_point(color ="blue") +labs(title ="Exponentielle Beziehung", x ="X", y ="Y") +theme_minimal()
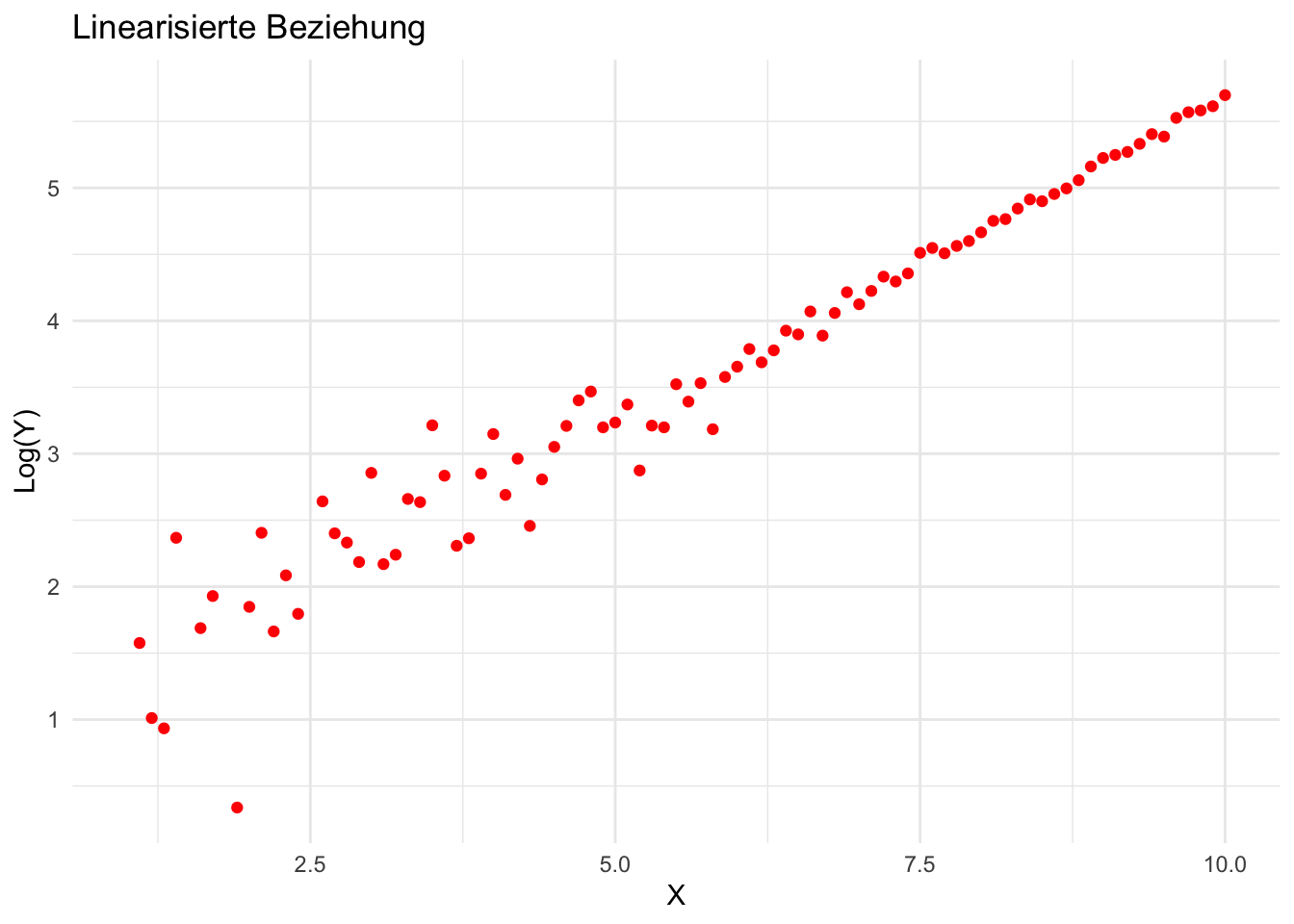
log_y <-log(y) # Log-Transformation von Ydf <-data.frame(x = x, y = log_y)ggplot(aes(x = x, y = y), data = df) +geom_point(color ="red") +labs(title ="Linearisierte Beziehung", x ="X", y ="Log(Y)") +theme_minimal()
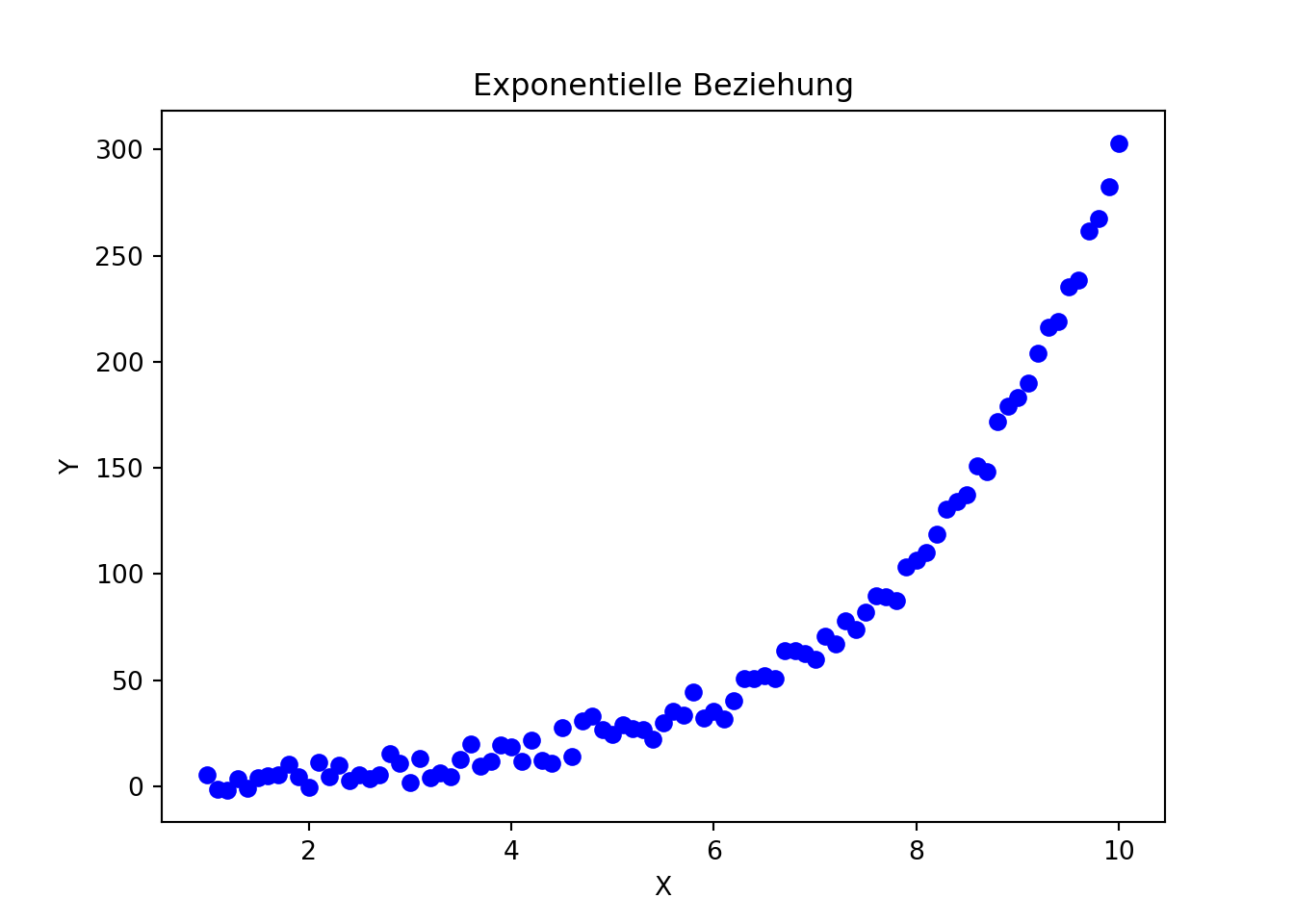
import numpy as npimport matplotlib.pyplot as plt# Beispiel in Python: Linearisierung einer exponentiellen Beziehungnp.random.seed(2009)x = np.arange(1, 10.1, 0.1)y =2* np.exp(0.5* x) + np.random.normal(0, 5, size=len(x) )plt.scatter(x, y, color='blue')plt.title('Exponentielle Beziehung')plt.xlabel('X')plt.ylabel('Y')plt.show()
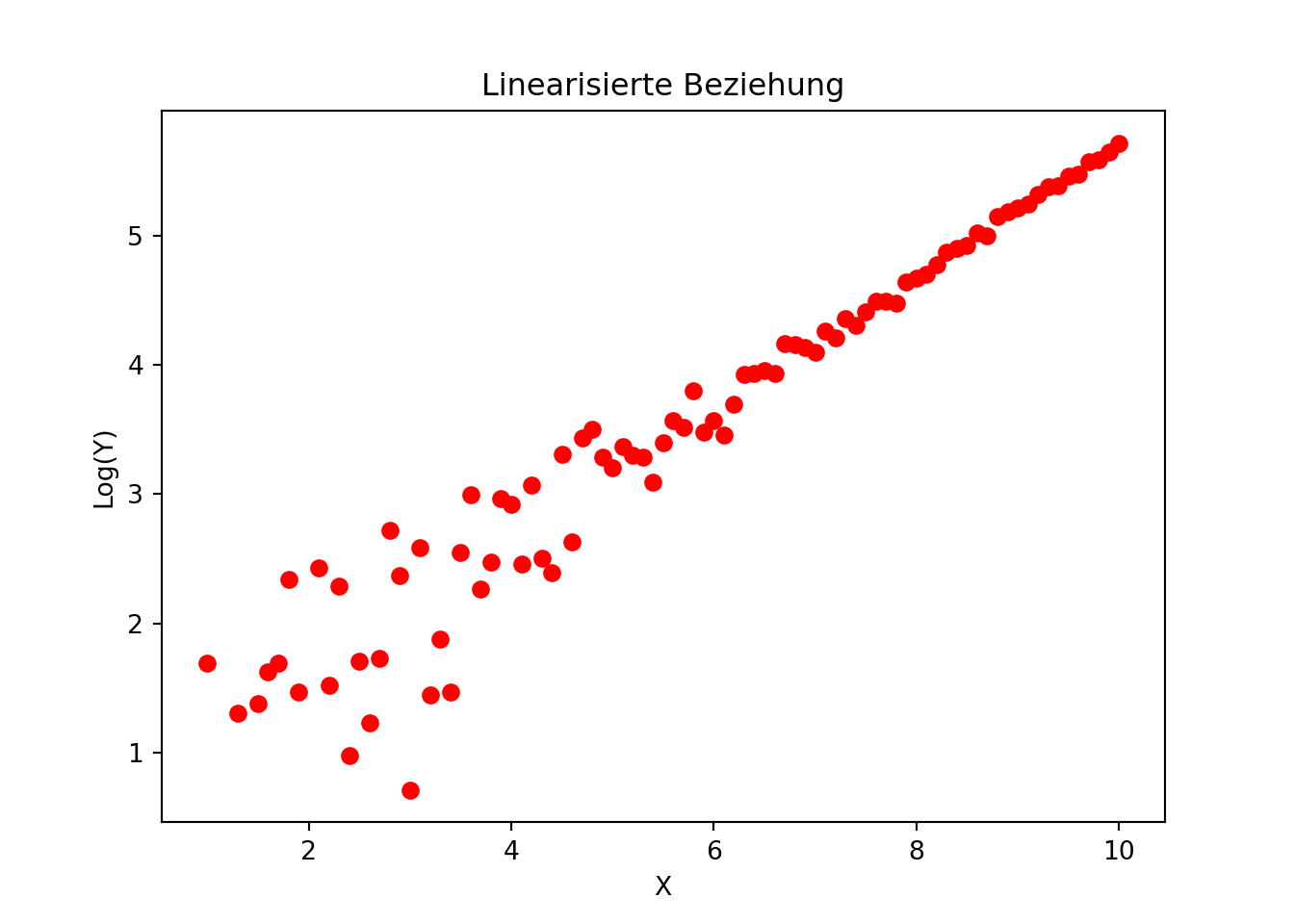
plt.clf()log_y = np.log(y) # Log-Transformation von Y
<string>:2: RuntimeWarning: invalid value encountered in log
Logarithmen sind besonders nützlich, um multiplikative Beziehungen zwischen Variablen zu modellieren. Wenn die Beziehung zwischen zwei Variablen durch eine Multiplikation beschrieben wird, kann die Anwendung des Logarithmus diese Beziehung in eine additive Form überführen, was die Analyse und Interpretation erleichtert. \[
y = a \cdot x_1^{b_1} \cdot x_2^{b_2} \cdots x_n^{b_n}
\] Durch die Anwendung des Logarithmus auf beide Seiten der Gleichung erhalten wir: \[
\log(y) = \log(a) + b_1 \cdot \log(x_1) + b_2 \cdot \log(x_2) +
\cdots + b_n \cdot \log(x_n)
\] Diese Transformation ermöglicht es, die multiplikative Beziehung als lineare Kombination der logarithmierten Variablen darzustellen, was die Anwendung von linearen Regressionsmethoden erleichtert.
In der Statistik und Datenanalyse wird diese Technik häufig verwendet, um Modelle zu erstellen, die besser zu den Daten passen und leichter zu interpretieren sind.
Zum Beispiel bei der log-likelihood-Funktion in der Maximum-Likelihood-Schätzung oder bei der Analyse von Wachstumsprozessen, bei denen die Wachstumsraten oft als multiplikative Effekte modelliert werden.
Wenn Statisiker log-likelihood-Funktionen verwenden, dann u.a. aus diesen Gründen:
Monotonie: Logarithmen sind streng monoton wachsend, was bedeutet, dass die Maximierung der log-likelihood-Funktion äquivalent zur Maximierung der ursprünglichen likelihood-Funktion ist. Dies erleichtert die Optimierung erheblich.
Produkte wandeln sich zu Summen: Für unabhängige Beobachtungen gilt
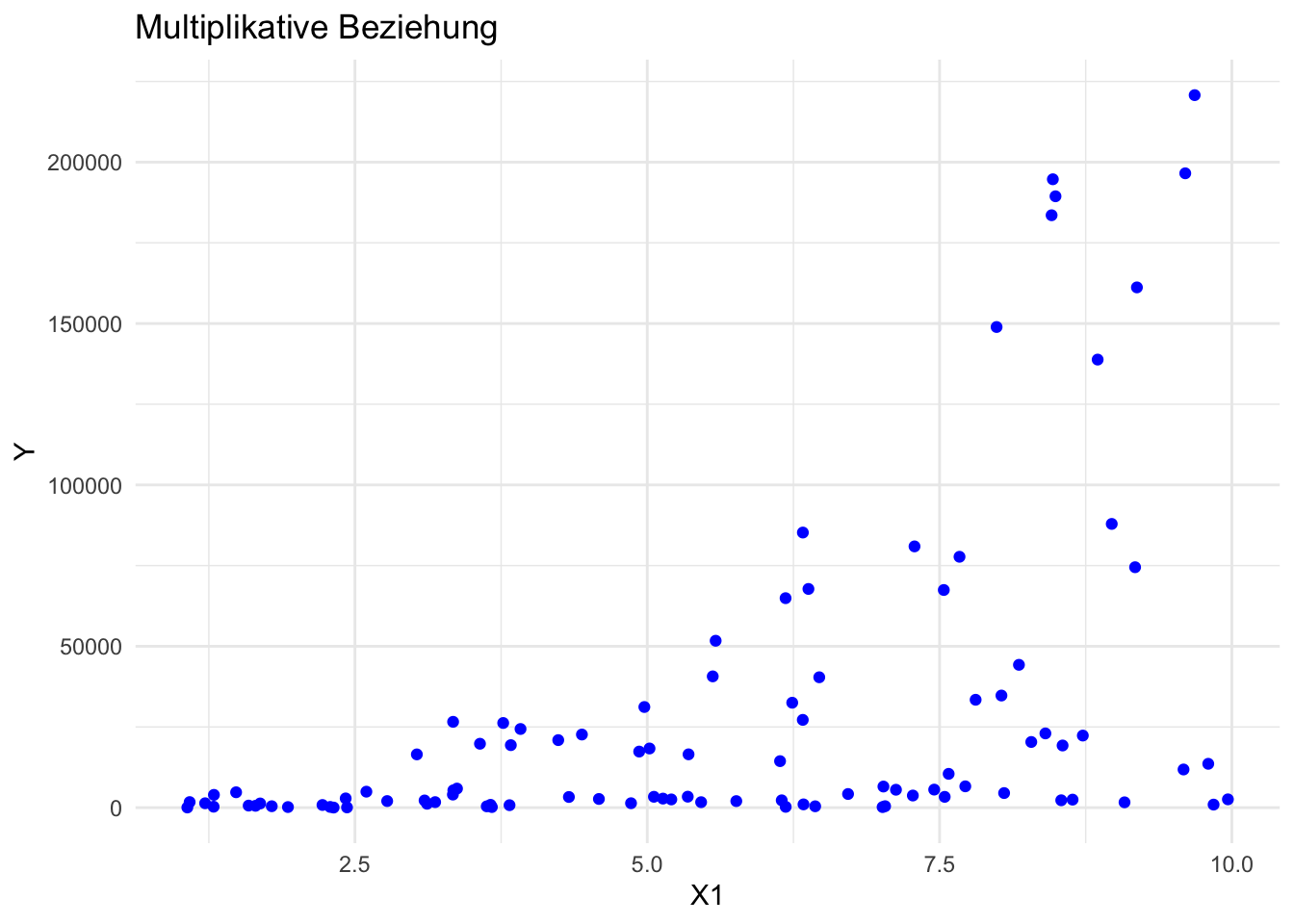
library(ggplot2)# Beispiel in R: Multiplikative Beziehungset.seed(2009)x1 <-runif(100, 1, 10)x2 <-runif(100, 1, 10)y <-3* x1^2* x2^3+rnorm(100 , mean =0, sd =10) # Multiplikative Beziehung mit Rauschendf <-data.frame(x1 = x1, x2 = x2, y = y)ggplot(aes(x = x1, y = y), data = df) +geom_point(color ="blue") +labs(title ="Multiplikative Beziehung", x ="X1", y ="Y") +theme_minimal()
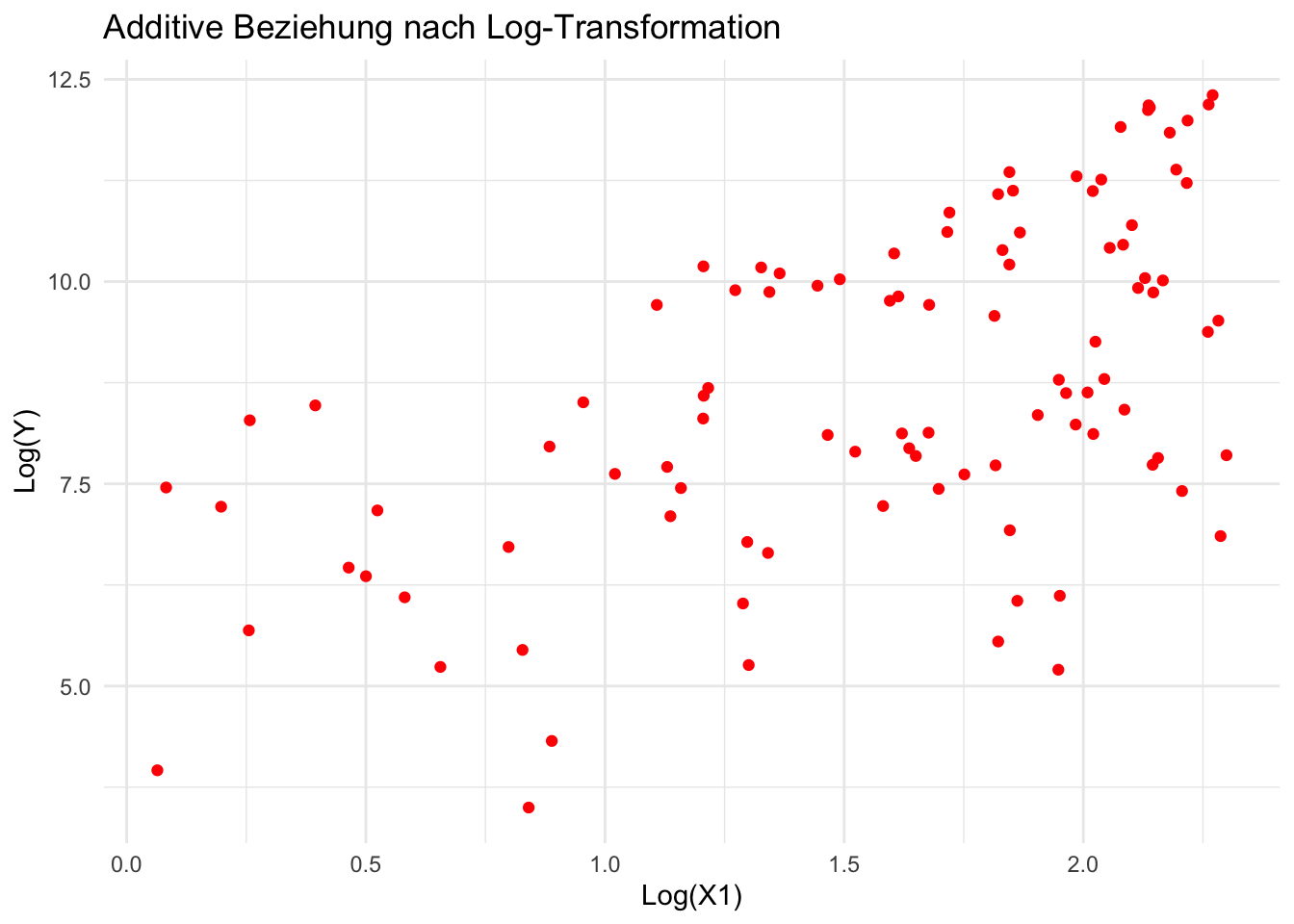
log_y <-log(y) # Log-Transformation von Ylog_x1 <-log(x1)log_x2 <-log(x2)df_log <-data.frame(x1 = log_x1, x2 = log_x2, y = log_y)ggplot(aes(x = x1, y = y), data = df_log) +geom_point(color ="red") +labs(title ="Additive Beziehung nach Log-Transformation", x ="Log(X1)", y ="Log(Y)") +theme_minimal()
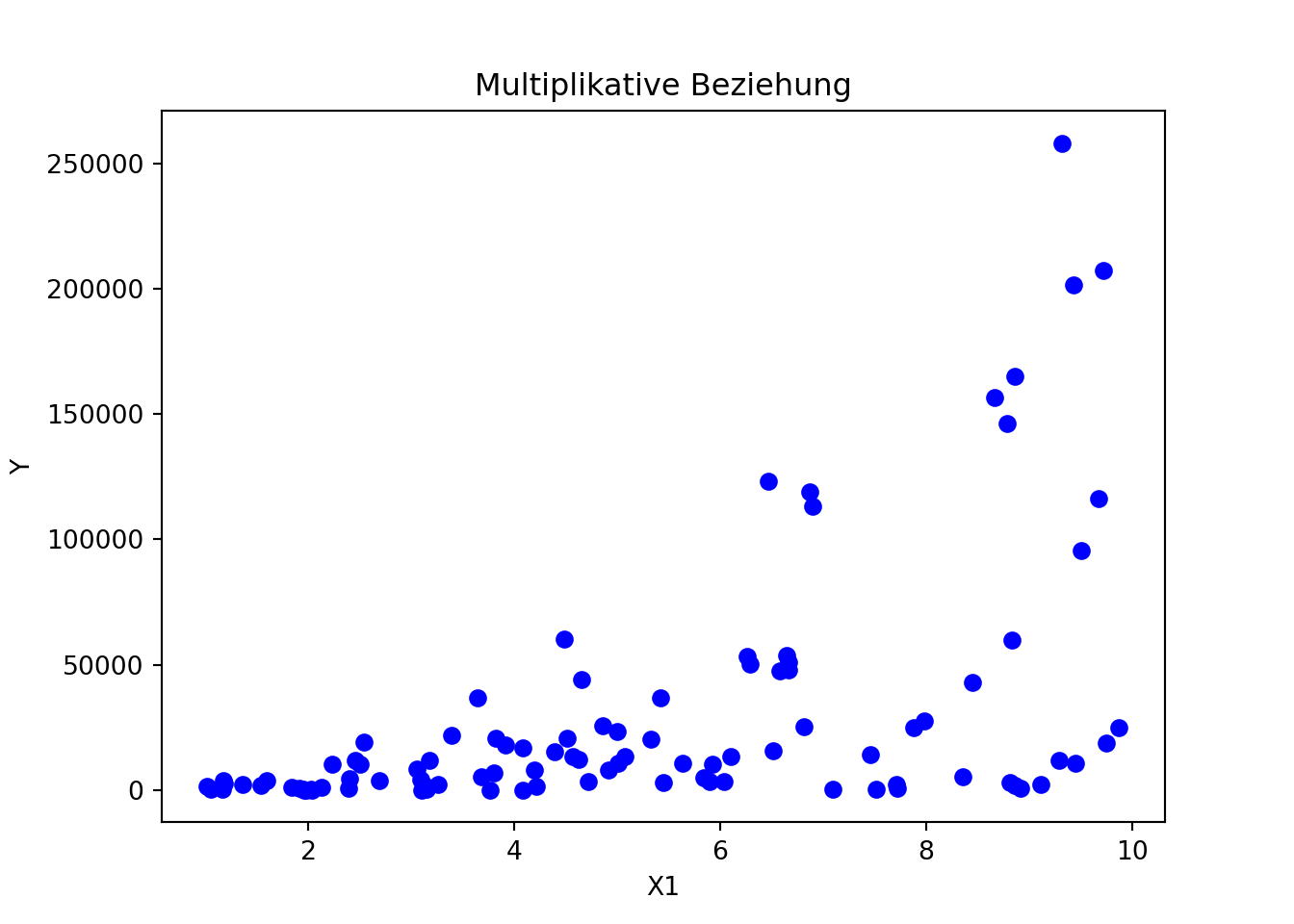
import numpy as npimport matplotlib.pyplot as pltnp.random.seed(2009)x1 = np.random.uniform(1, 10, 100)x2 = np.random.uniform(1, 10, 100)y =3* x1**2* x2**3+ np.random.normal(0, 10, size=100) # Multiplikative Beziehung mit Rauschenplt.scatter(x1, y, color='blue')plt.title('Multiplikative Beziehung')plt.xlabel('X1')plt.ylabel('Y')plt.show()
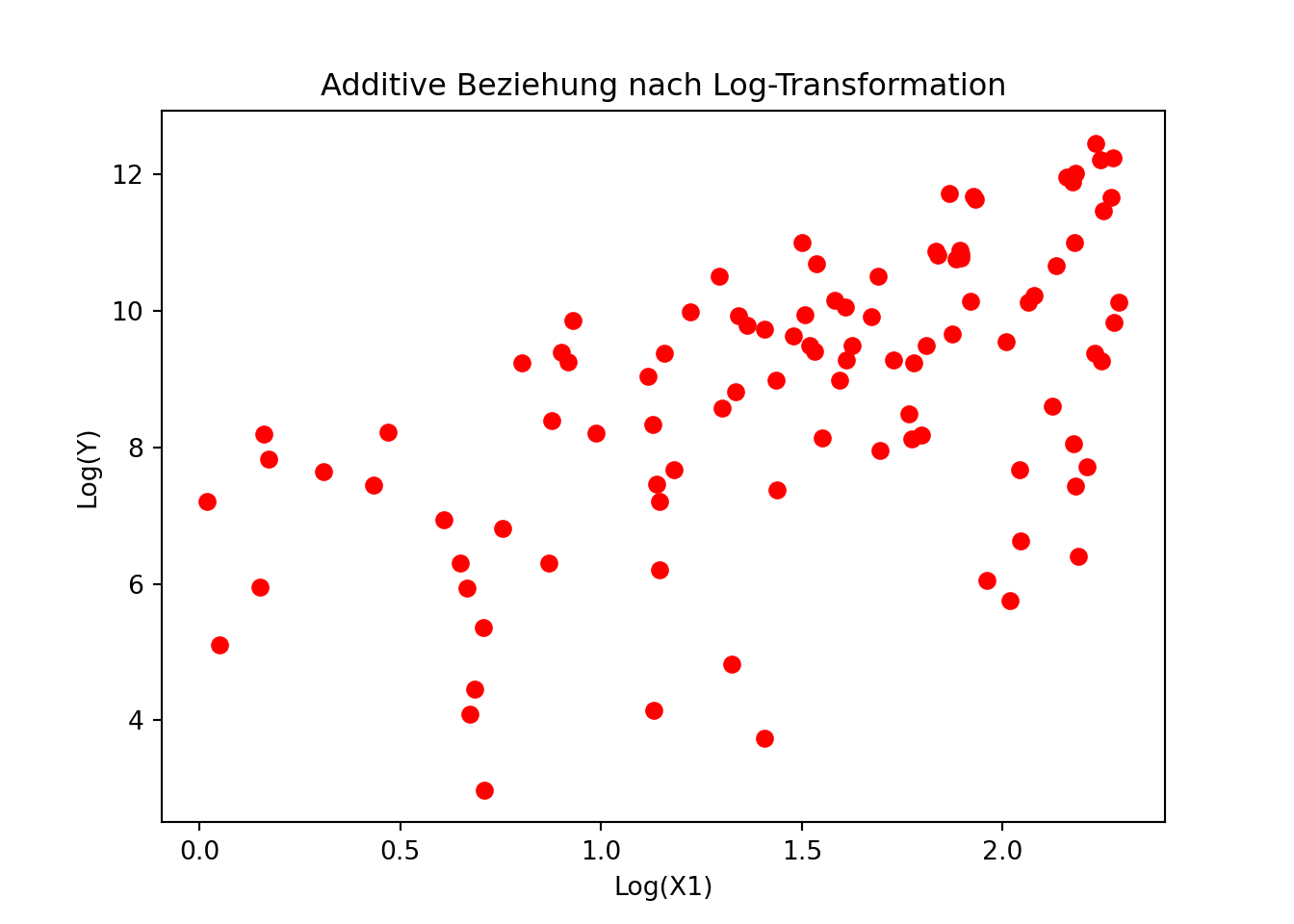
plt.clf()log_y = np.log(y) # Log-Transformation von Ylog_x1 = np.log(x1)log_x2 = np.log(x2)plt.scatter(log_x1, log_y, color='red')plt.title('Additive Beziehung nach Log-Transformation')plt.xlabel('Log(X1)')plt.ylabel('Log(Y)')plt.show()
plt.clf()
Fazit
Exponentiation und Logarithmen sind mächtige Werkzeuge in der Statistik, die es ermöglichen, Daten zu transformieren, Beziehungen zu modellieren und komplexe Phänomene zu verstehen. Durch die Anwendung dieser mathematischen Konzepte können Statistiker und Datenwissenschaftler tiefere Einblicke in ihre Daten gewinnen und präzisere Modelle erstellen.